Long Read Sequencing Market
Long Read Sequencing Market Size, Scope, Growth, Trends and By Segmentation Types, Applications, Regional Analysis and Industry Forecast (2025-2033)
Report ID : RI_706183 | Last Updated : August 17, 2025 |
Format : ![]()
![]()
![]()
![]()
Long Read Sequencing Market Size
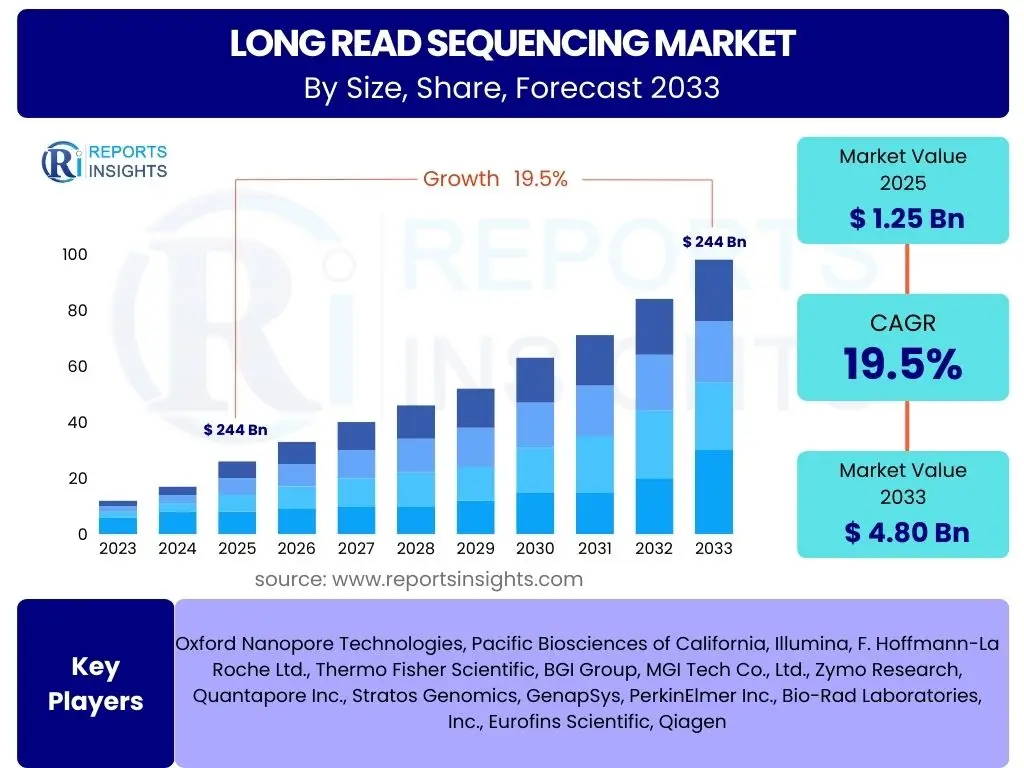
According to Reports Insights Consulting Pvt Ltd, The Long Read Sequencing Market is projected to grow at a Compound Annual Growth Rate (CAGR) of 19.5% between 2025 and 2033. The market is estimated at USD 1.25 billion in 2025 and is projected to reach USD 4.80 billion by the end of the forecast period in 2033. This substantial growth is primarily attributed to the increasing adoption of long read sequencing technologies across various research and clinical applications, driven by their ability to provide comprehensive genomic insights that short-read technologies cannot offer.
The expanding utility of long read sequencing in complex genomic regions, structural variant detection, and full-length transcript sequencing is a significant catalyst for this market expansion. Furthermore, continuous advancements in sequencing platforms, reduced costs, and improved data analysis tools are making these technologies more accessible and appealing to a broader range of end-users, including academic institutions, pharmaceutical companies, and clinical laboratories. This technological progression is fostering new applications and solidifying the market's upward trajectory.
Key Long Read Sequencing Market Trends & Insights
The Long Read Sequencing market is experiencing transformative trends, driven by continuous innovation and expanding applications that address the limitations of traditional short-read sequencing. Users frequently inquire about the latest technological advancements, such as enhanced read accuracy, increased throughput, and the development of more portable and affordable sequencing devices. These advancements are pivotal for making long read sequencing more accessible for diverse research and diagnostic purposes, moving beyond specialized genomic laboratories to broader clinical settings.
Another significant trend is the growing integration of long read sequencing into personalized medicine and clinical diagnostics. As the understanding of complex diseases deepens, there is an increasing demand for comprehensive genomic insights that can only be provided by long reads, particularly in areas like structural variant detection, epigenetics, and full-length gene isoform analysis. This shift is fueling investment in clinical validation and regulatory approvals for long read-based assays, reflecting a broader movement towards precision healthcare.
Furthermore, the market is witnessing an expansion into non-human applications, including agricultural genomics, environmental microbiology, and infectious disease surveillance. The ability of long read sequencing to provide rapid, comprehensive genomic data is proving invaluable for understanding pathogen evolution, optimizing crop yields, and monitoring biodiversity. This diversification of applications contributes significantly to the market's overall growth and resilience, attracting a wider range of stakeholders and research initiatives.
- Decreasing cost per base for long read sequencing, making it more competitive.
- Improved read accuracy and throughput across major long read platforms.
- Increased adoption in clinical diagnostics, particularly for rare diseases and cancer genomics.
- Emergence of portable and real-time sequencing devices for fieldwork and rapid diagnostics.
- Growing integration of long read data with multi-omics approaches for comprehensive biological insights.
- Expansion of applications in agricultural genomics, environmental science, and infectious disease monitoring.
AI Impact Analysis on Long Read Sequencing
Users frequently express interest in how Artificial Intelligence (AI) and machine learning are revolutionizing the analysis and utility of long read sequencing data, often asking about the specific benefits and challenges. AI's paramount impact lies in its capacity to process the voluminous and complex datasets generated by long read sequencing platforms, transforming raw signals into highly accurate genomic information. This includes enhancing base calling accuracy, improving de novo genome assembly, and precisely identifying structural variants that are often missed by conventional methods. AI algorithms can discern subtle patterns and correct errors, thereby increasing the reliability and utility of the sequencing data for research and clinical applications.
Beyond data processing, AI is significantly accelerating the pace of discovery in genomics by enabling more sophisticated interpretations of long read data. For instance, machine learning models can predict gene function, identify novel biomarkers, and even aid in drug target identification by analyzing complex genomic landscapes. This analytical power is crucial for translating vast amounts of genomic information into actionable biological insights, pushing the boundaries of what can be achieved in areas such as personalized medicine, disease stratification, and pathogen surveillance. The integration of AI tools is becoming indispensable for extracting maximum value from long read sequencing efforts.
However, the widespread adoption of AI in long read sequencing also presents challenges, which users frequently inquire about. These include the need for extensive computational resources, the development of robust and unbiased AI models, and the availability of skilled bioinformaticians capable of managing and interpreting AI-driven analyses. Ensuring data privacy and ethical considerations associated with AI processing sensitive genomic information are also critical concerns. Addressing these challenges through collaborative efforts and standardized practices will be key to fully harnessing AI's potential in the long read sequencing domain.
- Enhanced base calling accuracy and quality control through deep learning algorithms.
- Improved de novo genome assembly and scaffolding, particularly for complex and repetitive regions.
- More precise detection and characterization of structural variants and gene fusions.
- Accelerated data analysis pipelines, reducing the time from sequencing to actionable insights.
- Facilitation of complex data integration from multi-omics studies, revealing deeper biological correlations.
- Development of predictive models for disease risk, drug response, and biomarker discovery.
Key Takeaways Long Read Sequencing Market Size & Forecast
Common user questions regarding key takeaways from the Long Read Sequencing market size and forecast often revolve around the market's sustainability, the primary drivers of its expansion, and the long-term investment prospects. A central insight is the robust and sustained growth projected for the market, indicating its critical role in the future of genomics. This growth is not merely incremental but represents a foundational shift in how complex genomic questions are approached, moving beyond the limitations of short-read technologies to embrace comprehensive, high-fidelity sequencing. The market is poised for significant expansion, driven by continuous technological breakthroughs and an ever-broadening array of applications across research, clinical, and industrial sectors.
The market's trajectory is strongly influenced by increasing research and development expenditures in genomics, particularly within personalized medicine and complex disease diagnostics. The ability of long read sequencing to accurately detect structural variations, resolve repetitive genomic regions, and provide full-length transcript information is proving indispensable for these advanced applications. Consequently, investment in the long read sequencing market is viewed favorably, offering opportunities for innovation and market penetration as the technology matures and becomes more widely adopted in routine clinical practice.
Furthermore, the long-term outlook for the long read sequencing market is highly positive due to its inherent advantages in resolving complex genomic architectures and its potential to unlock new biological discoveries. The decreasing cost of sequencing, coupled with improvements in data analysis and automation, will continue to lower barriers to entry and accelerate adoption. These factors collectively underscore a market characterized by strong innovation, expanding utility, and a promising financial outlook, making it a pivotal area within the broader life sciences industry.
- The Long Read Sequencing market is projected for substantial growth, indicating its strategic importance in genomics.
- Technological advancements, particularly in accuracy and throughput, are key enablers of market expansion.
- Increased adoption in personalized medicine and clinical diagnostics is a primary growth driver.
- The market presents significant investment opportunities driven by expanding applications and technological maturity.
- Cost reductions and improved bioinformatics tools are lowering barriers to entry for new users.
Long Read Sequencing Market Drivers Analysis
The Long Read Sequencing market is primarily driven by the escalating demand for comprehensive genomic information, which short-read technologies often struggle to provide for complex genomic regions and structural variations. The increasing global burden of chronic and infectious diseases necessitates detailed genetic analysis for accurate diagnosis, prognosis, and therapeutic stratification, pushing the adoption of technologies capable of delivering full genomic context. Furthermore, the continuous reduction in sequencing costs makes long read sequencing more accessible for large-scale research projects and a growing number of clinical applications.
Technological advancements are another significant driver, with ongoing improvements in read length, accuracy, and throughput across major platforms. These innovations enhance the utility of long read sequencing for diverse applications, from de novo genome assembly and epigenetics to transcriptomics and microbial genomics. The growing recognition of long reads' superiority in resolving complex genetic architectures and detecting previously undetectable variants is fueling their integration into research pipelines and clinical workflows globally. The push for personalized medicine and precision oncology also strongly supports the expansion of this market, as long reads offer a more complete picture of individual genetic profiles.
| Drivers | (~) Impact on CAGR % Forecast | Regional/Country Relevance | Impact Time Period |
|---|---|---|---|
| Increasing demand for comprehensive genomic insights | +5.0% | Global, particularly North America, Europe, APAC | 2025-2033 |
| Technological advancements in sequencing platforms | +4.5% | Global, driven by developed regions | 2025-2033 |
| Growing applications in personalized medicine & clinical diagnostics | +4.0% | North America, Europe, select APAC countries | 2026-2033 |
| Declining cost of long read sequencing | +3.5% | Global, increasing accessibility | 2025-2033 |
| Increased R&D funding for genomics & bioinformatics | +2.5% | North America, Europe, China | 2025-2030 |
Long Read Sequencing Market Restraints Analysis
Despite its significant growth potential, the Long Read Sequencing market faces several restraints that could impede its widespread adoption. One primary challenge is the high initial capital investment required for purchasing long read sequencing instruments, which can be prohibitive for smaller laboratories, academic institutions with limited budgets, or emerging markets. This barrier to entry restricts the market to well-funded research centers and large healthcare systems, limiting broader penetration.
Another significant restraint is the complexity associated with long read data analysis and the need for specialized bioinformatics expertise. Long read datasets are large and computationally intensive, requiring sophisticated algorithms and powerful computing infrastructure for accurate processing and interpretation. The shortage of skilled bioinformaticians capable of handling these complex data streams poses a considerable bottleneck, delaying research outcomes and increasing operational costs for end-users. Furthermore, the rapid evolution of technology often leads to steep learning curves and the need for continuous training, adding to the operational burden.
| Restraints | (~) Impact on CAGR % Forecast | Regional/Country Relevance | Impact Time Period |
|---|---|---|---|
| High initial capital expenditure for instruments | -3.5% | Global, particularly emerging economies | 2025-2030 |
| Complexity of data analysis & bioinformatics expertise gap | -3.0% | Global, more pronounced in less developed regions | 2025-2033 |
| Challenges in data storage and management | -2.0% | Global | 2025-2033 |
| Lack of standardized protocols and clinical guidelines | -1.5% | Global, especially for clinical adoption | 2026-2033 |
| Competition from established short-read sequencing technologies | -1.0% | Global | 2025-2028 |
Long Read Sequencing Market Opportunities Analysis
The Long Read Sequencing market is presented with significant opportunities arising from its expanding applications in clinical diagnostics and precision medicine. As the understanding of complex diseases progresses, there is an increasing recognition of the need for comprehensive genomic insights, including structural variants and full-length transcripts, which long read technologies uniquely provide. This growing clinical utility is paving the way for the development of new diagnostic assays, particularly for rare diseases, cancer profiling, and infectious disease surveillance, opening up vast, untapped market segments.
Another compelling opportunity lies in the emergence of portable and more accessible long read sequencing devices. Miniaturized sequencers offer the potential for point-of-care diagnostics, fieldwork, and decentralized sequencing in remote locations, significantly broadening the user base beyond large, centralized laboratories. This accessibility can drive adoption in areas previously limited by infrastructure or cost constraints, particularly in developing countries with unmet healthcare needs. Furthermore, the integration of long read sequencing with multi-omics approaches (e.g., epigenomics, proteomics) presents substantial opportunities for holistic biological discovery, driving novel research avenues and therapeutic developments.
| Opportunities | (~) Impact on CAGR % Forecast | Regional/Country Relevance | Impact Time Period |
|---|---|---|---|
| Expansion into routine clinical diagnostics & precision medicine | +4.8% | North America, Europe, parts of APAC | 2026-2033 |
| Development of portable & decentralized sequencing solutions | +4.2% | Global, particularly emerging markets | 2025-2033 |
| Integration with multi-omics for comprehensive biological insights | +3.7% | Global, academic & pharma research | 2025-2033 |
| Untapped potential in agriculture, environmental, and forensic genomics | +3.0% | Global, niche markets | 2027-2033 |
| Increasing government funding & public-private partnerships | +2.3% | North America, Europe, China | 2025-2030 |
Long Read Sequencing Market Challenges Impact Analysis
The Long Read Sequencing market faces persistent challenges related to the vast amount of data generated and the subsequent requirements for robust storage and computational infrastructure. The sheer volume of raw data from long read sequencing projects often overwhelms existing bioinformatics pipelines and storage capacities, presenting significant bottlenecks for research institutions and clinical laboratories. This necessitates continuous investment in high-performance computing and scalable data solutions, which can be costly and technically demanding, hindering the efficiency and accessibility of long read workflows.
Another critical challenge lies in ensuring the quality and standardization of long read sequencing data across different platforms and experimental designs. While accuracy has significantly improved, variations in error profiles and data characteristics between technologies can complicate comparative analyses and integration efforts. Establishing universally accepted benchmarks and best practices for data generation, processing, and interpretation is crucial for enhancing the reproducibility and reliability of long read sequencing results, especially as the technology moves into regulated clinical environments. Addressing these standardization gaps will be essential for building widespread trust and adoption within the scientific and medical communities.
| Challenges | (~) Impact on CAGR % Forecast | Regional/Country Relevance | Impact Time Period |
|---|---|---|---|
| Scalability of data storage and processing infrastructure | -2.8% | Global | 2025-2033 |
| Ensuring data quality and standardization across platforms | -2.5% | Global, particularly for clinical applications | 2026-2033 |
| Navigating complex regulatory pathways for clinical adoption | -2.2% | North America, Europe | 2027-2033 |
| Rapid technological obsolescence requiring continuous upgrades | -1.8% | Global | 2025-2030 |
| Ethical, legal, and social implications (ELSI) of genomic data | -1.0% | Global, regulatory bodies | 2025-2033 |
Long Read Sequencing Market - Updated Report Scope
This comprehensive report provides an in-depth analysis of the Long Read Sequencing market, offering a detailed segmentation and regional breakdown to provide a holistic view of the market's dynamics. The scope encompasses market size estimations, historical data analysis from 2019 to 2023, and future projections up to 2033, enabling stakeholders to understand past trends and future growth opportunities. The report delves into key market drivers, restraints, opportunities, and challenges, providing a strategic framework for decision-making in this rapidly evolving sector.
Furthermore, the report highlights the impact of emerging technologies and industry trends, including the significant role of Artificial Intelligence in data analysis and the expanding applications of long read sequencing in clinical diagnostics and precision medicine. A detailed competitive landscape analysis profiles key players, their strategies, and market positioning, offering insights into the competitive intensity and potential for collaboration. This comprehensive scope ensures that readers gain a thorough understanding of the Long Read Sequencing market's current state and its future trajectory, equipping them with the knowledge to capitalize on growth prospects.
| Report Attributes | Report Details |
|---|---|
| Base Year | 2024 |
| Historical Year | 2019 to 2023 |
| Forecast Year | 2025 - 2033 |
| Market Size in 2025 | USD 1.25 billion |
| Market Forecast in 2033 | USD 4.80 billion |
| Growth Rate | 19.5% |
| Number of Pages | 245 |
| Key Trends |
|
| Segments Covered |
|
| Key Companies Covered | Oxford Nanopore Technologies, Pacific Biosciences of California, Illumina, F. Hoffmann-La Roche Ltd., Thermo Fisher Scientific, BGI Group, MGI Tech Co., Ltd., Zymo Research, Quantapore Inc., Stratos Genomics, GenapSys, PerkinElmer Inc., Bio-Rad Laboratories, Inc., Eurofins Scientific, Qiagen |
| Regions Covered | North America, Europe, Asia Pacific (APAC), Latin America, Middle East, and Africa (MEA) |
| Speak to Analyst | Avail customised purchase options to meet your exact research needs. Request For Analyst Or Customization |
Segmentation Analysis
The Long Read Sequencing market is meticulously segmented to provide a detailed understanding of its diverse components and growth avenues. The segmentation by technology primarily distinguishes between Nanopore Sequencing and SMRT (Single Molecule Real-Time) Sequencing, each offering unique advantages in terms of read length, throughput, and error profiles, catering to different research and clinical requirements. Synthetic Long Read Sequencing also constitutes a smaller, specialized segment. Understanding these technological nuances is crucial for market participants to identify areas of innovation and competitive differentiation.
Further segmentation includes products, which encompass instruments, consumables, and various services such as sequencing services, data analysis services, and bioinformatics software. This categorization helps in assessing the revenue contribution of each product type and the demand for supporting infrastructure and expertise. Applications form a critical segment, ranging from fundamental research areas like de novo sequencing and structural variation detection to specialized fields such as RNA sequencing (Isoform Sequencing), epigenetics, microbial genomics, and cancer research. The diverse applications underscore the versatility and increasing adoption of long read sequencing across the scientific and medical communities.
Finally, the market is segmented by end-users, including academic and research institutions, pharmaceutical and biotechnology companies, hospitals and clinics, and contract research organizations (CROs). This segmentation highlights the primary consumers of long read sequencing technologies, reflecting their varying needs, research priorities, and investment capacities. Analyzing these segments provides a granular view of market demand, adoption patterns, and strategic opportunities for companies targeting specific user groups within the long read sequencing ecosystem.
- By Technology:
- Nanopore Sequencing
- SMRT Sequencing
- Synthetic Long Read Sequencing
- By Product:
- Instruments
- Consumables
- Services
- Sequencing Services
- Data Analysis Services
- Bioinformatics Software
- By Application:
- De Novo Sequencing
- Structural Variation Detection
- RNA Sequencing (Isoform Sequencing)
- Epigenetics
- Microbial Genomics
- Cancer Research
- Human Genomics
- Agricultural & Animal Research
- Others
- By End-User:
- Academic & Research Institutions
- Pharmaceutical & Biotechnology Companies
- Hospitals & Clinics
- Contract Research Organizations (CROs)
- Others
Regional Highlights
- North America: Dominates the Long Read Sequencing market due to extensive research and development activities, significant government and private funding for genomic projects, a robust presence of leading market players, and high adoption rates of advanced sequencing technologies in clinical diagnostics and pharmaceutical research. The region benefits from a well-established healthcare infrastructure and a strong focus on personalized medicine initiatives.
- Europe: Represents a substantial market share driven by strong academic and research institutions, increasing healthcare expenditure, and a growing emphasis on genomic research for rare diseases and cancer. Countries like the UK, Germany, and France are at the forefront of adopting long read sequencing technologies, supported by public funding and collaborative research networks.
- Asia Pacific (APAC): Emerging as the fastest-growing region, propelled by increasing investments in healthcare infrastructure, a rising prevalence of chronic diseases, expanding genomic research initiatives in countries like China, India, and Japan, and a growing awareness of personalized medicine. Government support for biotech and genomics R&D, coupled with a large patient pool, contributes significantly to market expansion.
- Latin America: Shows promising growth potential driven by improving healthcare access, increasing awareness of genomic medicine, and emerging research collaborations. While still nascent compared to developed regions, the adoption of long read sequencing is gradually increasing, particularly in Brazil and Mexico, for infectious disease research and agricultural genomics.
- Middle East and Africa (MEA): Experiences gradual growth, primarily in advanced economies like Saudi Arabia, UAE, and South Africa, due to increasing healthcare investments and a focus on developing local research capabilities. However, challenges related to infrastructure and skilled personnel may limit widespread adoption in some parts of the region.

Top Key Players
The market research report includes a detailed profile of leading stakeholders in the Long Read Sequencing Market.- Oxford Nanopore Technologies
- Pacific Biosciences of California
- Illumina
- F. Hoffmann-La Roche Ltd.
- Thermo Fisher Scientific
- BGI Group
- MGI Tech Co., Ltd.
- Zymo Research
- Quantapore Inc.
- Stratos Genomics
- GenapSys
- PerkinElmer Inc.
- Bio-Rad Laboratories, Inc.
- Eurofins Scientific
- Qiagen
Frequently Asked Questions
What is Long Read Sequencing?
Long Read Sequencing (LRS), also known as third-generation sequencing, is a technology that can read DNA or RNA sequences much longer than conventional short-read methods, typically thousands to millions of base pairs. This capability allows for more comprehensive analysis of complex genomic regions, structural variations, and full-length gene isoforms, providing a more complete picture of an organism's genetic makeup.
What are the primary applications of Long Read Sequencing?
The primary applications of Long Read Sequencing include de novo genome assembly, accurate detection of structural variants, full-length RNA sequencing for isoform identification, epigenetics (e.g., direct detection of DNA methylation), microbial genomics, and complex disease research such as cancer and rare inherited disorders. It is also increasingly used in agricultural research and infectious disease surveillance.
How does Long Read Sequencing compare to Short Read Sequencing?
Long Read Sequencing offers significantly longer reads compared to Short Read Sequencing (which typically generates reads of 50-300 base pairs). This enables LRS to resolve complex genomic regions, accurately detect large structural variations, and provide better genome assembly. While short-read sequencing is cost-effective for variant calling in known regions, LRS is superior for discovering novel variants and understanding genomic architecture.
What are the main advantages of using Long Read Sequencing?
The main advantages of Long Read Sequencing include its ability to resolve challenging genomic regions like repetitive sequences, provide direct detection of epigenetic modifications, offer comprehensive structural variant calling, and enable full-length isoform sequencing without reassembly. These capabilities lead to more accurate and complete genomic analyses, enhancing biological discovery and clinical insights.
What are the future prospects for the Long Read Sequencing market?
The future prospects for the Long Read Sequencing market are very strong, driven by continuous technological advancements leading to lower costs, higher accuracy, and increased throughput. Expanding applications in personalized medicine, clinical diagnostics, and point-of-care testing are expected to fuel significant growth. Integration with AI for data analysis will further enhance its utility and broaden its adoption across diverse fields.
| Single User | : $3680 |
|---|---|
| Multi User | : $5680 |
| Corporate User | : $6400 |
Buy Now
Secure SSL Encrypted
